Den InMemoryDataProvider gibt es schon länger. Ich habe hier schon einmal darüber geschrieben. Allerdings gibt es eine wichtige Einschränkung: Dieser Provider unterstützt keine Relationen, die sich nicht aus Schlüsselfeldern ergeben. Man kann daher nicht einfach ein XML darin „verpacken“, er eignet sich nur für „flache“ Formate wie CSV oder XLS. Die grundlegende Technologie war aber damit schon länger vorhanden. Das hat mich dann, als ich diesen Wunsch in unserem Idea Place gelesen habe, auf die Idee gebracht, das Ganze auf beliebige Data-Provider-Strukturen zu erweitern.
Das Ergebnis ist der InMemoryDataProviderWrapper. Die Verwendung ist sehr simpel:
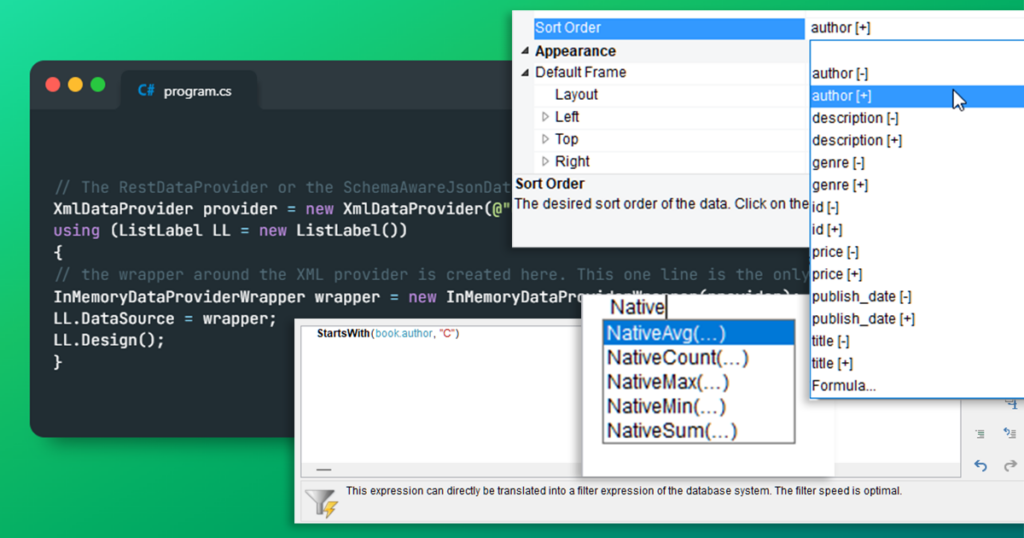
// The RestDataProvider or the SchemaAwareJsonDataProvider are also suitable here
XmlDataProvider provider = new XmlDataProvider(@"c:\temp\text.xml");
using (ListLabel LL = new ListLabel())
{
// the wrapper around the XML provider is created here. This one line is the only change
InMemoryDataProviderWrapper wrapper = new InMemoryDataProviderWrapper(provider);
LL.DataSource = wrapper;
LL.Design();
}
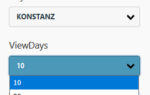
Der Clou dabei ist, dass die Struktur durch das Wrappen nicht verändert wird, d.h. die Projektdateien, die bereits für das XML angelegt wurden, können unverändert bleiben. Das Test-XML für diesen Blogpost stammt von hier. Und wo bisher – ohne den Wrapper – keine Sortierungen zur Verfügung standen, kann jetzt bei ansonsten völlig identischer Struktur eine Sortierung gewählt werden:
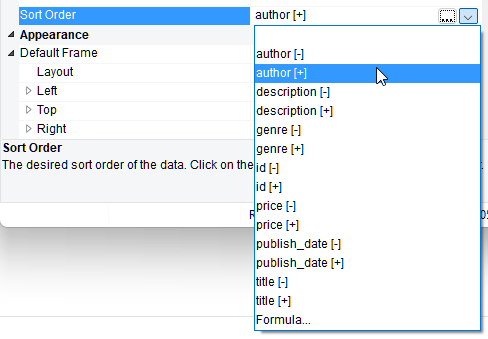
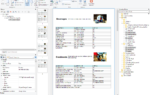
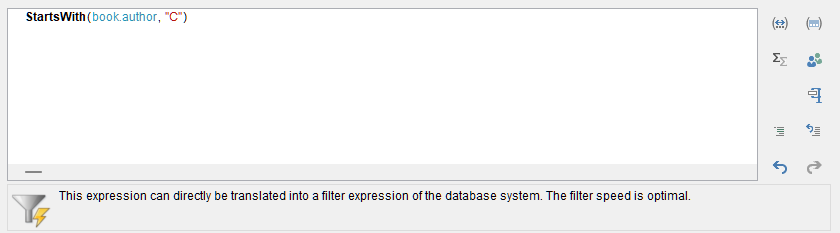
Ebenso kann mit nativen Filtern gearbeitet werden:
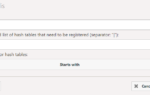
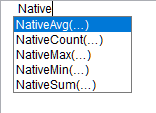
Eine Reihe an nativen Aggregatsfunktionen steht ebenfalls zur Verfügung:
Dabei geht der Provider so speichersparend wie möglich vor – Tabellen werden erst dann in den Speicher geladen, wenn sie auch wirklich benötigt werden. Es findet also kein vollständiges Caching der (möglicherweise sehr umfangreichen) Datei statt, sondern ein Caching-on-demand. Und wenn die Features irgendwann doch nicht mehr benötigt werden, kann der Wrapper jederzeit wieder entfernt werden, ohne dass die Projektdateien geändert werden müssen.
Vielen Dank an dieser Stelle für die Anregung im Idea Place. Ich freue mich über diesen neuen Mitbewohner in unserem Datenprovider-Zoo.

Jochen Bartlau leitet als Geschäftsführer die Softwareentwicklung bei combit. Microsoft .NET und Agiles Projektmanagement sind zwei seiner Steckenpferde. Der technikbegeisterte Physiker und Vanlife-Enthusiast verbringt seine Freizeit am liebsten beim Wandern.