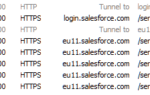
Seit einigen Versionen prüft List & Label bei Datenbankabfragen, welche Identifiers/Felder im Projekt tatsächlich genutzt werden und übergibt nur diese. Allerdings war diese Infomation nur global für die Datenbank und nicht für einzelne Tabellen verfügbar. Ein einfaches Beispiel: Wenn Sie früher eine Tabelle zweimal gedruckt haben, einmal mit den Feldern „FirstName“, „Name“, „Address“ und „City“ und dann mit einem Diagramm die Felder „Revenue“ und „City“ ergaben sich insgesamt fünf Identifiers („FirstName“, „Name“, „Address“, „City“, „Revenue“).
Bis LL23 übergibt der Databinding-Mechanismus die fünf Identifiers zweimal an den Bericht, einmal für die Tabelle und einmal für das Diagramm. LL23 unterscheidet nun zwischen den beiden Objekten und übergibt jeweils nur die benötigten Daten. Dadurch werden, je nach Größe Ihrer Datenbank, die Last auf Ihrem Datenbankserver immens gesenkt und unzählige API Aufrufe gespart. Ihre selbst geschriebenen Datenpovider profitieren davon bereits durch geringfügige Änderungen.
Ein weiterer gigantischer Performancezuwachs hängt damit zusammen: Wenn Berichtsparameter zum Filtern der Daten genutzt werden (beispielsweise der Parameter „City“), wurde bisher in LL22 der komplette Eintrag sogar dreimal übergeben. LL23 erkennt, dass der Parameter lediglich bestimmte Werte benötigt und optimiert die Abfrage bereits auf der Datenbankebene. Anstelle von
SELECT FirstName, Name, Address, City, Revenue FROM Customers
und dem Sammeln der bestimmten Städte in der Druckengine wird jetzt einfach nur ein
SELECT DISTINCT City FROM Customers
geschickt, was unendlich schneller ist.
Seeing is believing: Untenstehende Animationen zeigen den Vergleich zwischen LL22 und LL23 mit exakt dem selben Bericht.
LL22
LL23
Wo wir gerade bei der Performance sind: Wir haben auch den Speicherbedarf der Kreuztabelle extrem verbessert. Sie erkennen das insbesondere beim Druck von Kreuztabellen mit mehreren Schattenseiten. LL23 hat jetzt nur noch etwa den halben Speicherbedarf wie noch LL22.

Jochen Bartlau leitet als Geschäftsführer die Softwareentwicklung bei combit. Microsoft .NET und Agiles Projektmanagement sind zwei seiner Steckenpferde. Der technikbegeisterte Physiker und Vanlife-Enthusiast verbringt seine Freizeit am liebsten beim Wandern.